

Elasticsearch는 내부적으로 문서 기반 저장 구조와 역인덱스(index)를 활용하여 빠른 검색 성능을 제공합니다.
Elasticsearch의 인덱스, 샤드, 세그먼트 등의 전체 아키텍처를 인덱스 단위부터 클러스터 단위까지 정리해보도록 하겠습니다.
데이터 흐름 개요
Elasticsearch에서 데이터는 다음과 같은 흐름을 따릅니다.
- 입력: JSON 기반의 API, 데이터 파이프라인(예: Logstash, Beats) 등을 통해 데이터가 유입됩니다.
- 처리: 데이터를 파싱하고 분석기에 의해 토큰화합니다.
- 저장: 문서는 인덱스에 저장되며, 인덱스는 내부적으로 여러 샤드(shard)로 분할됩니다.
- 검색: 역인덱스를 통해 빠른 검색이 가능하고, 각 노드의 샤드를 통해 병렬로 처리됩니다.
인덱스, 샤드, 세그먼트 구조
인덱스(Index)
데이터를 저장하는 최상위 단위로, SQL의 테이블과 유사합니다.
샤드(Shard)
하나의 인덱스는 여러 샤드로 분할되어 저장됩니다. 샤드는 데이터를 저장하고 질의 처리를 담당하는 최소 단위입니다.
샤드는 내부적으로 세그먼트(segment)라는 더 작은 단위로 나뉘며, 이는 파일 시스템에 저장됩니다. 세그먼트는 시간이 지나면서 병합되고, 새로운 세그먼트가 생성됩니다.

샤드와 복제본의 구조 및 장애 복구
복제본(Replica)
- 각 샤드는 복제본(replica)을 가질 수 있으며, 다른 노드에 분산 저장됩니다.
- 복제본은 읽기 요청 처리와 장애 복구를 위한 용도로 사용됩니다.
- 복제본은 절대로 동일한 노드에 배치되지 않습니다. 이는 고가용성을 위한 기본 조건입니다.

샤드와 복제본 예시
- 노드 A에는 샤드 1과 복제본 2, 3이 배치되어 있습니다.
- 노드 B에는 샤드 2, 3과 복제본 1이 존재합니다.
- 이처럼 샤드와 해당 복제본은 서로 다른 노드에 분산 배치됩니다.
장애 발생 시 복제본 승격
- 노드 A가 다운되면, 그 안에 있던 샤드 1은 사용할 수 없게 됩니다.
- 이 때, 노드 B에 있던 복제본 1이 자동으로 샤드 1로 승격되어 클러스터의 안정성이 유지됩니다.
- Elasticsearch는 이 과정을 자동으로 감지하고 조치합니다.

상태 값 (클러스터 상태 색상)
- green: 모든 샤드와 복제본이 정상적으로 배치된 상태
- yellow: 주 샤드는 모두 있지만 복제본이 부족한 상태
- red: 일부 샤드 자체가 배치되지 않아 데이터 접근 불가
노드와 클러스터 구조
노드(Node)
Elasticsearch의 실행 단위로, 하나의 물리 서버 또는 가상 머신입니다. 각 노드는 데이터를 저장하고 질의를 처리할 수 있습니다.
하나의 노드에는 여러 개의 샤드가 배치될 수 있습니다. 단일 인덱스의 샤드들도 여러 노드에 분산되어 저장될 수 있습니다.
클러스터(Cluster)
여러 노드가 모여 하나의 클러스터를 구성합니다.

역인덱스 구조
문서 기반 검색의 핵심은 역인덱스 구조에 있습니다.
예를 들어, "hello world"라는 문장이 두 문서에 있을 때, 단어 기준으로 각각의 문서 번호를 매핑해 저장함으로써 특정 단어가 포함된 문서를 빠르게 찾을 수 있게 됩니다.

분석기와 토큰화
Elasticsearch는 분석기를 통해 텍스트를 토큰으로 분리합니다. 이 과정을 통해 자연어를 인덱싱할 수 있게 됩니다.
- Standard analyzer: 기본 분석기. 공백과 구두점을 기준으로 토큰화합니다.
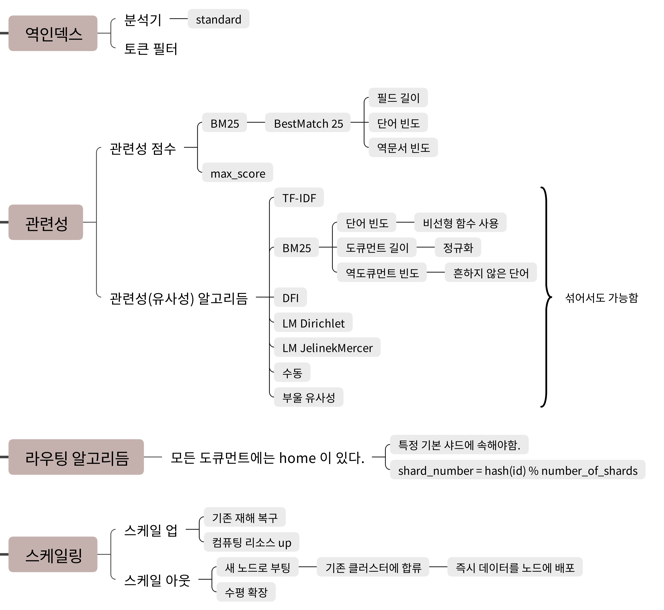
관련성 점수와 알고리즘
Elasticsearch에서 검색 결과는 단순히 일치하는 문서를 반환하는 것이 아니라, 관련성 점수(relevance score)를 기반으로 랭킹이 매겨진 상태로 정렬됩니다. 이 점수는 사용자가 입력한 질의(Query)와 각 문서의 연관도를 수치화한 결과입니다.
관련성 점수 산정 방식
기본적으로 Elasticsearch는 BM25 알고리즘을 사용합니다. 검색 결과의 정렬 기준은 각 문서가 계산한 score 값이며, 이는 max_score 필드로 반환됩니다.
관련성 점수에 영향을 주는 요소
관련성 점수는 다음과 같은 요소에 의해 결정됩니다.
- 단어 빈도 (TF, Term Frequency)
문서 내 특정 단어가 많이 등장할수록 관련성이 높다고 간주됩니다. - 역문서 빈도 (IDF, Inverse Document Frequency)
전체 문서에서 드물게 등장하는 단어일수록 더 높은 가중치를 갖습니다. - 문서 길이 정규화
문서가 지나치게 길어지면, 관련성 점수가 낮아지도록 보정됩니다. - 필드 길이와 필드 빈도
질의 대상 필드의 길이도 점수에 영향을 줄 수 있습니다.
관련성 알고리즘 종류
Elasticsearch는 BM25 외에도 다양한 유사성 알고리즘을 제공하며, 필요에 따라 선택적으로 사용할 수 있습니다.
TF-IDF (Term Frequency – Inverse Document Frequency)
가장 전통적인 알고리즘으로, 단어의 빈도와 역문서 빈도를 곱하여 점수를 계산합니다. 현재는 기본값은 아니지만 일부 환경에서는 여전히 사용 가능합니다.
- 단어 빈도
- 비선형 함수 사용
- 드문 단어에 가중치 부여
BM25 (BestMatch 25)
Elasticsearch의 기본 알고리즘. TF-IDF의 문제점을 개선한 형태로, 정규화와 문서 길이 보정이 강화되어 있습니다.
- 혼잡하지 않은 단어를 더 우선시
- 과도한 단어 반복에 대한 영향 완화
커스텀 유사성 모델
Elasticsearch에서는 플러그인을 통해 사용자 정의 유사성 모델도 적용 가능합니다. 기본 제공되는 모델 외에, 특정 도메인에 최적화된 가중치 적용이 필요할 때 활용할 수 있습니다.
관련성 알고리즘 섞어 쓰기
Elasticsearch는 검색 대상 필드마다 서로 다른 유사성 알고리즘을 사용할 수 있도록 지원합니다. 예를 들어, title 필드에는 BM25를, description 필드에는 TF-IDF를 사용할 수 있습니다.
샤딩과 스케일링 전략
Elasticsearch는 수평 확장을 지원합니다. 인덱스는 샤드로 나뉘고, 샤드는 여러 노드에 분산되어 저장됩니다. 이로 인해 시스템은 더 많은 데이터를 저장하고, 더 많은 질의를 병렬로 처리할 수 있습니다.
해시 함수를 통해 샤드 번호가 정해지며, 특정 문서는 고정된 샤드에 매핑됩니다.
shard_number = hash(id) % number_of_shards
'ELK' 카테고리의 다른 글
| [Elasticsearch] 인기 검색어 구현하기 (1) (2) | 2025.11.07 |
|---|---|
| [Elastic search] 다중 필터 검색, 자동 완성 (0) | 2025.08.23 |
| Elastic search in action 4장 - 매핑 (2) | 2025.08.06 |
| Elastic search in action - 2장 (8) | 2025.08.04 |
| 성능 최적화 - 모니터링 시스템 구축 (3) (1) | 2025.04.04 |