



매핑 개요
매핑의 정의
엘라스틱서치에서 매핑(mapping)은 각 문서(document)의 필드와 그 필드에 저장되는 데이터 타입을 정의하는 스키마(schema)입니다. 이를 통해 검색 성능 최적화 및 데이터의 일관성을 유지할 수 있습니다.
첫 도큐먼트 인덱스 생성 시 동작
별도의 명시적인 스키마 정의 없이도 문서를 인덱싱할 수 있으며, 이 경우 동적 매핑(dynamic mapping)이 적용됩니다. 동작 순서는 다음과 같습니다.
- 설정에 따라 인덱스가 자동 생성됩니다.
- 필드의 값을 분석하여 적절한 데이터 타입을 추론하고, 이에 따라 새로운 매핑이 생성됩니다.
- 문서가 저장되며, 이 시점에 스키마가 함께 구성됩니다.
- 이후 같은 필드를 가진 문서들은 이 매핑을 그대로 참조합니다.
필드와 분석기 설정
문서 내 각 필드는 기본적으로 text 타입 또는 keyword 타입으로 처리되며, 분석기 설정에 따라 처리 방식이 달라집니다.
예를 들어 text 타입은 기본 분석기를 통해 토큰화되며, keyword 타입은 전체 값이 하나의 토큰으로 인식됩니다.
추가로 noop analyzer를 사용하면 토큰 분할 없이 전체 필드를 하나로 처리할 수 있습니다.
동적 매핑
타입 추론 메커니즘
동적 매핑은 다음과 같은 방식으로 타입을 자동 추론합니다.
- 날짜 형식 (yyyy-MM-dd, yyyy-MM-dd'T'HH:mm:ss)
- 숫자 타입 (long, float, double)
- boolean 값 (true, false)
동적 매핑의 한계
자동 매핑은 편리하지만 아래와 같은 오류가 발생할 수 있어 주의가 필요합니다.
- 잘못된 타입 추론: 예를 들어 "2"가 문자열이지만 정수로 추론되어 int로 저장되는 경우
- 날짜 형식 파싱 실패: dd-MM-yyyy 형식처럼 예상치 못한 포맷일 경우
- keyword 타입의 예상치 못한 사용: 예컨대 두 번째 필드만 keyword로 지정되어 일관되지 않을 수 있음
명시적 매핑
매핑 생성 방법
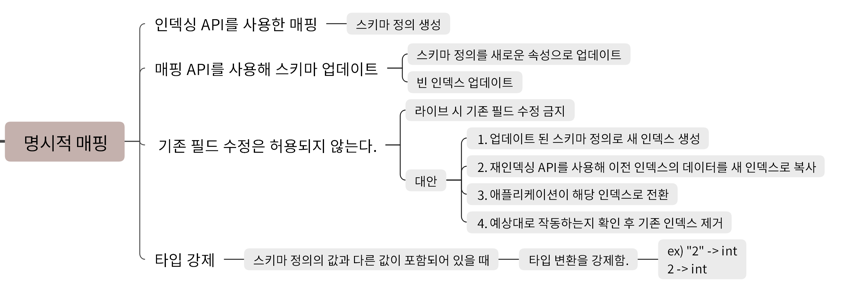
명시적 매핑은 인덱스 생성 시 또는 매핑 API를 통해 사전에 정의된 필드 타입과 속성으로 스키마를 설정하는 방식입니다.
- 인덱싱 API를 통한 스키마 정의
- 매핑 API를 사용해 기존 스키마 업데이트 (예: 빈 필드 추가, 속성 변경 등)
기존 필드 수정 불가 및 우회 방법
라이브 인덱스에서 이미 정의된 필드의 타입은 수정할 수 없습니다. 이럴 경우 다음과 같은 방법으로 대응합니다.
- 기존 인덱스를 새로운 스키마로 재정의
- 기존 데이터를 새로운 인덱스로 복사
- 애플리케이션에서 새로운 인덱스를 참조
- 기존 인덱스 제거 후 신규 인덱스 적용
타입 강제 변환
스키마 정의 값과 다른 값이 들어오는 경우, 예를 들어 문자열 "2"를 int로 지정된 필드에 저장하려 할 때 변환이 강제됩니다. 이는 데이터의 무결성에 영향을 줄 수 있으므로 사전에 필드 타입을 명확히 정의하는 것이 좋습니다.
데이터 타입
단순 타입
텍스트, 숫자, 날짜, 불린 등 기본적인 데이터 표현을 위한 타입입니다.
- text, keyword, constant_keyword, wildcard
- date, date_range
- long, integer, float, double, scaled_float
- boolean
- ip, ip_range
복합 타입
중첩된 데이터 구조나 관계를 표현할 수 있는 고급 타입입니다.
- object: 평탄화된 구조, 객체 저장 가능
- nested: 내부 객체 간 관계 보존 (bool 검색 쿼리 등과 함께 사용)
- flattened: 키-값 구조의 대용량 필드에 적합
- join: 부모-자식 관계 표현 가능
특수 타입
지리적 좌표, IP, 범위 등의 특수 목적 필드 타입입니다.
- geo_point: 위도와 경도를 나타냄
- geo_shape: 다각형, 선, 원 등의 도형 지원
- ip: IPv4, IPv6
- range: 숫자/날짜 범위 지정 (gt, gte, lt, lte 등)
고급 데이터 타입
geo_point
위도(lat)와 경도(lon) 정보를 다양한 형식으로 저장할 수 있는 필드입니다.
- Array: [lon, lat]
- String: "lat,lon"
- GeoHash
- Point: { "lat": 37.0, "lon": 127.0 }
object
- 계층적 데이터 구조 표현
- 개별 도큐먼트로 저장되지 않음
- 배열 내에서의 관계는 보존되지 않음 → 복합 쿼리 사용 필요
nested
- object 구조보다 더 정밀한 관계 표현 가능
- 내부 객체 간의 관계성 유지
- bool 쿼리와 리프 쿼리로 필터링 가능
flattened
- 동적 키-값 구조를 가진 필드에서 유용
- 모든 키를 keyword 타입으로 인식
- 매핑에 대한 명시적 정의가 불가능하다는 제약 있음
join
- 문서 간 부모-자식 관계를 설정할 수 있는 타입
- 스키마 설계 시 명확하게 정의되어야 함
search_as_you_type
- 검색어 자동완성 기능을 위해 설계된 타입
- n-gram 방식으로 토큰 생성하여 예측 검색 지원
다중 데이터 타입
하나의 필드에 여러 데이터 타입을 동시에 정의할 수 있습니다.
- fields 속성 사용
- 예: 하나의 필드에 text와 keyword를 모두 설정해 다양한 검색 전략 지원
'ELK' 카테고리의 다른 글
| [Elasticsearch] 인기 검색어 구현하기 (1) (2) | 2025.11.07 |
|---|---|
| [Elastic search] 다중 필터 검색, 자동 완성 (0) | 2025.08.23 |
| Elastic search in action 3장 - 아키텍처 (4) | 2025.08.05 |
| Elastic search in action - 2장 (8) | 2025.08.04 |
| 성능 최적화 - 모니터링 시스템 구축 (3) (1) | 2025.04.04 |