저번 포스팅에서는 Nori tokenizer의 핵심 자료 구조인 Lattice(격자) 구조를 정리해보았습니다.
2025.11.11 - [ELK] - [Elasticsearch] Nori Tokenizer 파헤치기 - Lattice 구조
[Elasticsearch] Nori Tokenizer 파헤치기 - Lattice 구조
Elasticsearch를 활용하여 한글 기반 검색을 구현하다가 Nori Tokenizer를 사용하게 되었습니다. 형태소 단위로 토큰을 분석하는 것이 흥미로웠습니다. Lucene의 NoriTokenizer 내부 구현, 특히 Viterbi lattice 기
featherdale.tistory.com
이번 포스팅에서는 Lattice 구조를 어떻게 활용하여 분석을 하게되는지 살펴보도록 하겠습니다.
개요
Viterbi는 문장에 대해 가능한 분석(형태소 시퀀스) 경로들 중 총비용이 가장 작은 경로를 찾는 동적계획법 알고리즘입니다. HMM/품사 전이 모델(POS)에서 최적 경로를 구하는 표준 기법을 말합니다.
Viterbi의 목표
Viterbi의 목표는 다음 목적함수를 최소화하는 경로를 찾는 것입니다.
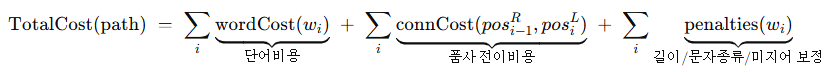
- w: i번째 형태소 노드,
- pos: 그 노드의 left/right 품사 ID
- wordCost: 사전 빈도/우선도 기반 고정비용
- connCost: 전이 행렬(품사 bigram)에서 가져오는 비용
- penalties: 숫자/기호/미지어 길이 등의 경험적 보정
즉, 사전에 있고, 품사 전이가 자연스러운 경로가 유리하도록 비용을 설계하는 것이 목적입니다.
Viterbi 동작 순서
Viterbi가 동작하는 순서는 다음과 같습니다.
- BOS/EOS를 포함해 격자 뼈대 마련
- 사전/미지어/사용자 사전으로 후보 노드 채우기
- Forward DP: 전이비용+단어비용(+패널티) 누적, 각 노드의 bestPrev 결정
- Backtrace: EOS에서 bestPrev 따라가며 최적 경로 복구
- Emit(방출): 경로의 노드를 토큰으로 변환(표면형/기본형/품사/offset, decompound 옵션 등)
위 내용을 좀 더 자세하게 다뤄보도록 하겠습니다.
Viterbi의 목적 함수
w_i : i번째 형태소 노드
w_i는 입력 문장에서 특정 위치에 해당하는 형태소 후보입니다.
예를 들어 “학생회관에” 에서는
- w₁ = “학생”
- w₂ = “회관”
- w₃ = “에”
이런 식으로 나눠집니다.
즉, w_i는 문장에서 i번째 단어 또는 형태소라는 뜻입니다.
Viterbi는 이런 형태소들의 연결(w₁ → w₂ → w₃ …)을 경로로 보고, 그 경로의 총 비용을 계산해서 가장 자연스러운 문장 해석을 찾습니다.
pos_i^L / pos_i^R : 품사 전이 정보 (왼쪽/오른쪽 품사 ID)
이건 각 형태소가 문법적으로 어떤 품사와 연결될 수 있는지를 나타내는 정보입니다.
- pos_i^L (Left POS ID): 이 형태소가 앞 단어와 연결될 때의 품사 ID
- pos_i^R (Right POS ID): 이 형태소가 뒤 단어와 연결될 때의 품사 ID
“학생(명사)” → “회관(명사)” 은 부자연스럽지만,
“학생(명사)” → “회관(명사파생복합어)” 은 자연스러울 수 있습니다.
이때 전이 가능성(자연스러움의 정도)을 ConnectionCosts 행렬에서 찾게 됩니다.
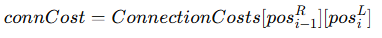
즉, 이 값이 낮을수록 이 품사 연결은 자연스럽다는 뜻입니다.
wordCost : 단어 자체의 기본 비용
이건 형태소 그 자체에 부여된 기본 점수입니다.
사전(Dictionary)에 등록된 단어들은 각자 빈도, 중요도에 따라 기본비용이 다릅니다.
- 많이 쓰이는 단어 → 비용 낮음 (선호됨)
- 드물거나 긴 단어 → 비용 높음 (덜 선호됨)
| 단어 | wordCost | 의미 |
| 학생 | 1000 | 일반 명사, 자주 등장 |
| 학생회관 | 1200 | 복합명사, 상대적으로 덜 등장 |
| 학생회 | 1300 | 특정 의미, 덜 자주 등장 |
이건 형태소 후보 자체가 얼마나 자연스러운 단어인지를 반영한 값입니다.
connCost : 품사 전이(transition) 비용
이건 앞 단어의 품사와 뒤 단어의 품사가 연결될 때의 자연스러움을 수치화한 비용입니다.
| 이전 품사 (Right ID) | 다음 품사 (Left ID) | connCost | 의미 |
| 명사 | 조사 | 50 | 자연스러움 ↑ |
| 명사 | 명사 | 400 | 약간 부자연스러움 |
| 조사 | 동사 | 150 | 문법적으로 가능 |
| 조사 | 조사 | 1000 | 거의 불가능 |
그래서 문장 내의 각 단어가 이어질 때마다, 전이 행렬(ConnectionCosts) 에서 이 값을 가져와서 누적하는 형태입니다.

penalties : 패널티 (보정항)
이건 단어 자체의 품질을 보정하는 추가비용을 뜻합니다. 실제 언어는 단순히 품사 전이만으로 설명이 안 되기 때문에,
몇 가지 경험적 규칙을 가산해서 조정합니다.
| 상황 | 패널티 | 이유 |
| 미지어(unknown) | +500 | 사전 밖 단어는 신뢰도↓ |
| 너무 긴 단어 | +300 | 지나치게 긴 토큰은 오분석일 확률↑ |
| 특수문자/이모지 | +700 | 형태소 분석 대상이 아님 |
| 한 글자 미지어 | +200 | 너무 짧은 단위는 의미 불명확 |
| 숫자 시퀀스 | +100 | 종종 별도로 처리됨 |
즉, penalties는 언어적 직관을 보정하기 위한 추가비용입니다.
Viterbi 동작 원리
위에서 간략하게 설명한 동작 순서를 자세하게 알아보도록 하겠습니다.
Lattice 격자 뼈대 마련 (BOS/EOS 포함)
Lattice에 대해서는 저번 포스팅에 알아보았습니다.
- x축 (가로축): 입력 문자의 위치 (offset)
- y축 (세로축): 해당 위치에서 가능한 형태소 후보들
- 노드(node): 형태소 후보 (단어, 품사, 사전 ID, 비용 등)
- 엣지(edge): 형태소 간 연결 가능성 (품사 전이 가능 여부)
추가로, 문장의 논리적 시작/끝을 위해 BOS/EOS 가상 노드를 둡니다.
BOS → [pos=0 후보…] → [pos=… 후보…] → [pos=n 후보…] → EOS
이 격자가 Viterbi의 DP 테이블이 됩니다.
후보 노드 채우기 (사전/미지어/사용자 사전)
각 문자 위치(pos)마다 사전, 사용자 사전, 미지어(unknown) 사전에서 형태소 후보를 찾아 ViterbiNode 로 만든 뒤 lattice에 삽입합니다.
Forward DP (전이비용 + 단어비용 + 패널티 누적, bestPrev 결정)
각 노드의 totalCost 를 계산하면서 최소 비용을 갱신하고, 그 때의 이전 노드(bestPrev) 를 기록합니다.
// lucene/analysis/nori/viterbi/ViterbiSearcher.java
private void forwardSearch(ViterbiLattice lattice) {
for (int pos = 0; pos <= lattice.getEndPos(); pos++) {
for (ViterbiNode cur : lattice.getNodes(pos)) {
int bestCost = Integer.MAX_VALUE;
ViterbiNode bestPrev = null;
for (ViterbiNode prev : lattice.getNodes(cur.getStartPos())) {
if (prev.getEndPos() != cur.getStartPos()) continue;
int transition = connCosts.get(prev.getRightId(), cur.getLeftId());
int cost = prev.getTotalCost()
+ transition
+ cur.getWordCost()
+ computePenalty(cur);
if (cost < bestCost) {
bestCost = cost;
bestPrev = prev;
}
}
cur.setTotalCost(bestCost);
cur.setBestPrevNode(bestPrev);
}
}
}// lucene/analysis/ko/dict/ConnectionCosts.java
public int get(int leftId, int rightId) {
return costTable[leftId * numRight + rightId];
}Backtrace (EOS → bestPrev 따라가기)
Forward 단계가 끝나면 EOS에서 bestPrev 포인터를 거슬러 올라가며 최소 비용 경로를 복원합니다.
거꾸로 추적한 뒤 순서를 뒤집어 최종 시퀀스를 얻습니다.
// lucene/analysis/nori/viterbi/ViterbiSearcher.java
private List<ViterbiNode> backtrace(ViterbiNode eosNode) {
List<ViterbiNode> result = new ArrayList<>();
ViterbiNode node = eosNode.getBestPrevNode();
while (node != null && node.getType() != TokenType.BOS) {
result.add(node);
node = node.getBestPrevNode();
}
Collections.reverse(result);
return result;
}Emit (방출: 형태소 토큰 출력)
복원된 최적 경로의 각 노드를 Token 객체로 변환하여 출력합니다.
복합명사 분해(decompound) 옵션이나 불용 품사 필터링 등이 이 단계에서 적용됩니다.
// lucene/analysis/ko/KoreanTokenizer.java
private void emit(List<ViterbiNode> bestPath) {
for (ViterbiNode node : bestPath) {
Token token = new Token(node.getSurface(), node.getStartOffset(), node.getEndOffset());
token.setPartOfSpeech(node.getPosTag());
// 복합명사 처리 옵션
if (decompoundMode == DecompoundMode.MIXED) {
emitDecompoundedTokens(node);
}
outputToken(token);
}
}정리
Lucene Nori가 만들어진 목적을 살펴보았고, 목적 함수가 동작하는 방식을 확인하였습니다.
Input text
↓
[BOS/EOS 추가 → 격자 구성]
↓
[사전/미지어 후보 노드 추가]
↓
[Forward DP: totalCost + bestPrev 계산]
↓
[Backtrace로 최적 경로 복원]
↓
[Emit 단계에서 Token 생성/출력]위 과정을 통해 Lattice 구조를 이용하여 Viterbi 알고리즘이 작동하는 방식을 알아보았습니다.
정리해보자면 Nori의 형태소 분석, 즉 Viterbi알고리즘은 가능한 모든 형태소 경로 중에서 단어비용 + 전이비용 + 보정비용의 총합이 가장 작은 경로를 찾는 최적화 과정입니다.
'ELK' 카테고리의 다른 글
| [Elasticsearch] 검색 최적화하기 (2) - 마이그레이션(reindex) (1) | 2025.12.17 |
|---|---|
| [Elasticsearch] 검색 최적화하기 (1) - analyzer (0) | 2025.12.15 |
| [Elasticsearch] Nori Tokenizer 파헤치기 (1) - Lattice 구조 (0) | 2025.11.11 |
| [Elasticsearch] 인기 검색어 구현하기 (2) (0) | 2025.11.10 |
| [Elasticsearch] 인기 검색어 구현하기 (1) (2) | 2025.11.07 |