2025.11.07 - [ELK] - [Elasticsearch] 인기 검색어 구현하기 (1)
[Elasticsearch] 인기 검색어 구현하기 (1)
개요sns 프로젝트 중, 인기 검색어 저장이라는 파트를 담당하게 되었습니다.요구사항에 따라 어떻게 설계할 지 고민했던 부분을 정리하고자 간략하게 작성하게 되었습니다.결론부터 말씀드리면
featherdale.tistory.com
저번 글에 redis와 elasticsearch를 활용하여 인기 검색어를 관리하는 것으로 결정하였습니다.
이어서, 이번 글에서는 어떤 방식으로 redis와 elasticsearch를 활용하였는지 설명하도록 하겠습니다.
(※ Redis Sentinel과 Elasticsearch 클러스터링 구조는 다음 글에서 다루겠습니다.)

Redis 활용
redis를 어떻게 활용했는지 설명하기 전에 간단히 짚고 넘어가자면, redis는 인메모리 데이터베이스입니다. Persistence와 Performance의 균형을 맞추자는 원칙에 맞추어 설계 되었습니다. 따라서, 기본적으로 RDBMS에 비해 휘발될 가능성이 존재한다는 단점과, 속도가 빠르다는 장점을 가지고 있습니다.
Redis는 다양한 자료구조를 제공하며, 이 중에서도 이번 구현에서는 ZSET(Sorted Set) 구조를 활용하였습니다.
자료구조에 관한 글은 이전에 정리해 두었으니 확인해주시면 좋을 것 같습니다.
https://featherdale.tistory.com/11
[Redis] 레디스의 기본 개념 (1) - 자료 구조 및 명령어
2025.04.09 - [redis] - [Redis] 레디스의 기본 개념 (2) - 레디스에서 키를 관리하는 법 [Redis] 레디스의 기본 개념 (2) - 레디스에서 키를 관리하는 법Redis에서 키를 관리하는 방법Redis는 단순한 Key-Value 저
featherdale.tistory.com
ZSET은 다른 자료구조와 달리 score 기반 정렬이 가능하고,
TTL(만료 시간) 을 설정할 수 있다는 장점이 있습니다.
덕분에 ‘검색어 + 검색 횟수(score)’ 형태의 데이터를 관리하기에 매우 적합했습니다.
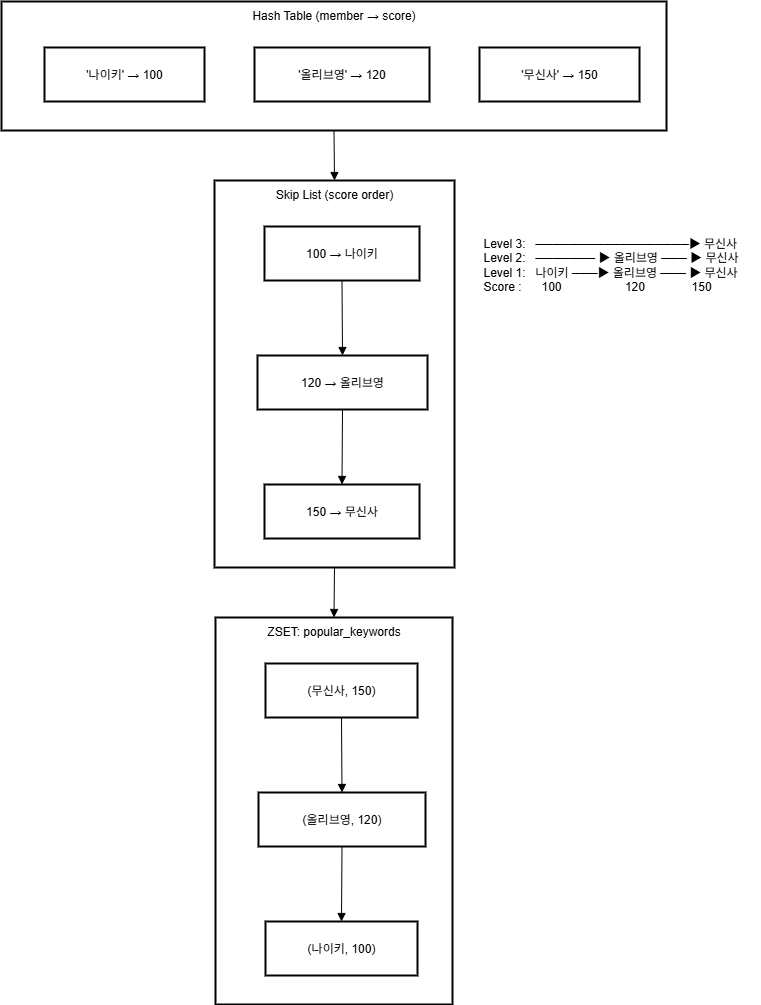
설계 배경
문제점을 다시 짚어보면 다음과 같았습니다.
- autocomplete을 구현해야할 것.
- elasticsearch에 쓰기 또는 변경 요청을 줄일 것.
인기 검색어 시스템의 특성상 조회·생성·수정 요청이 매우 빈번하게 발생합니다. 하지만 비즈니스적으로 보았을 때,
일정 기간의 데이터가 유실되더라도 큰 문제가 없을 것으로 판단하였습니다. 따라서 데이터 유실 가능성을 감수하더라도 속도와 처리 효율이 중요한 Redis를 선택하였습니다.
이때, 모든 검색어 데이터를 전부 Elasticsearch에 인덱싱할 필요는 없었기 때문에,
Redis에 임시 저장한 뒤 일정 검색량(Score) 이상인 데이터만 Elasticsearch로 반영하도록 설계하였습니다.
이 과정을 통해 Elasticsearch에 과도한 쓰기 부하가 발생하지 않도록 제어하였습니다.
결과적으로 Redis와 Elasticsearch를 Write-behind 구조로 구성함으로써, Elasticsearch의 세그먼트 병합(Merge) 과정에서 발생할 수 있는 부하를 줄이고, 전체적인 시스템 성능을 안정적으로 유지할 수 있었습니다.
Elasticsearch 활용
Elasticsearch는 장애 발생 시 레플리카 샤드가 자동으로 대체되어 고가용성을 유지하며, 역색인과 Trie 기반 구조(FST) 를 이용하여 문서 내용 기반의 검색과 자동완성 기능을 효율적으로 수행합니다. 글의 제목이 아닌 문서 내용으로 검색하거나, 자동완성(Autocomplete) 기능을 구현할 때에는 이러한 역색인 기반의 역참조 검색 구조가 매우 효과적입니다.
엘라스틱 서치 같은 경우 동작 원리는 간략하게 설명하도록 하겠습니다.
데이터 타입과 쿼리에 따라 analyzer가 작동 여부가 나뉩니다.
요구사항에 따라 도큐먼트를 저장하는 인덱스 설정과 analyzer, 데이터 타입과 쿼리를 설계해야 합니다.

텍스트 기반의 검색이 필요한 keyword 필드는 text 타입으로 지정하고, 한국어 형태소 분석을 위한 nori tokenizer와 자동완성 기능을 위한 edge_ngram filter를 조합한 사용자 정의 analyzer를 적용하였습니다.
반면, 정렬이나 점수 계산에 사용되는 score 필드는 integer 타입으로, 최신성 판단에 활용되는 updatedAt 필드는 date 타입으로 설정하여 analyzer가 동작하지 않도록 하였습니다.
필드의 성격에 따라 analyzer 적용 여부를 구분함으로써, 불필요한 토큰화나 검색 오차를 줄이면서도 자동완성과 연관검색이 가능한 인덱스를 구축할 수 있었습니다.
또한, Redis에서 Elasticsearch로 데이터를 반영할 때는 Bulk API를 활용하여 대량 동기화 시 발생할 수 있는 I/O 비용을 최소화하였습니다.
'ELK' 카테고리의 다른 글
| [Elasticsearch] Nori Tokenizer 파헤치기 (2) - Viterbi 알고리즘 (0) | 2025.11.12 |
|---|---|
| [Elasticsearch] Nori Tokenizer 파헤치기 (1) - Lattice 구조 (0) | 2025.11.11 |
| [Elasticsearch] 인기 검색어 구현하기 (1) (2) | 2025.11.07 |
| [Elastic search] 다중 필터 검색, 자동 완성 (0) | 2025.08.23 |
| Elastic search in action 4장 - 매핑 (2) | 2025.08.06 |